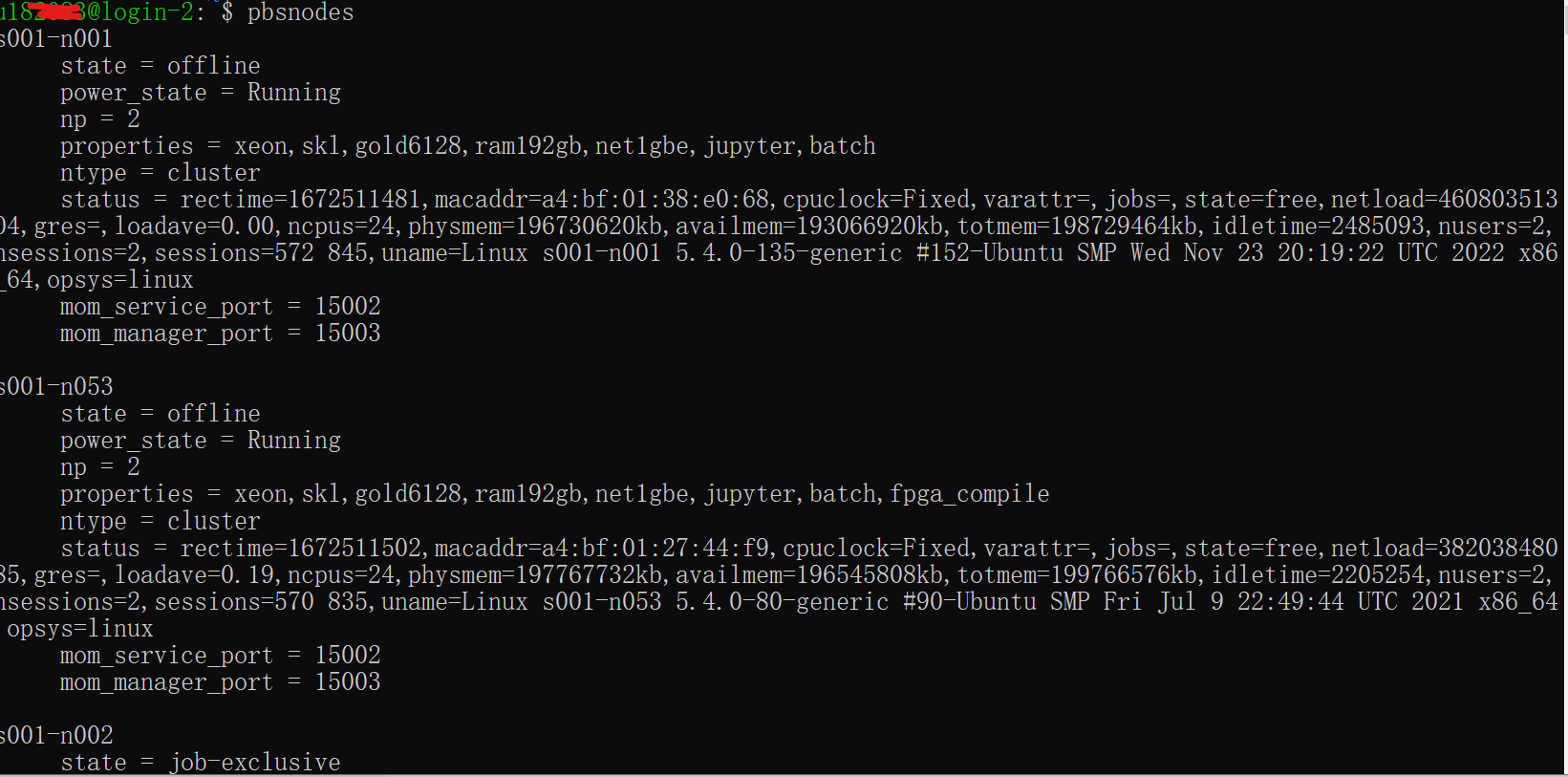
>
>
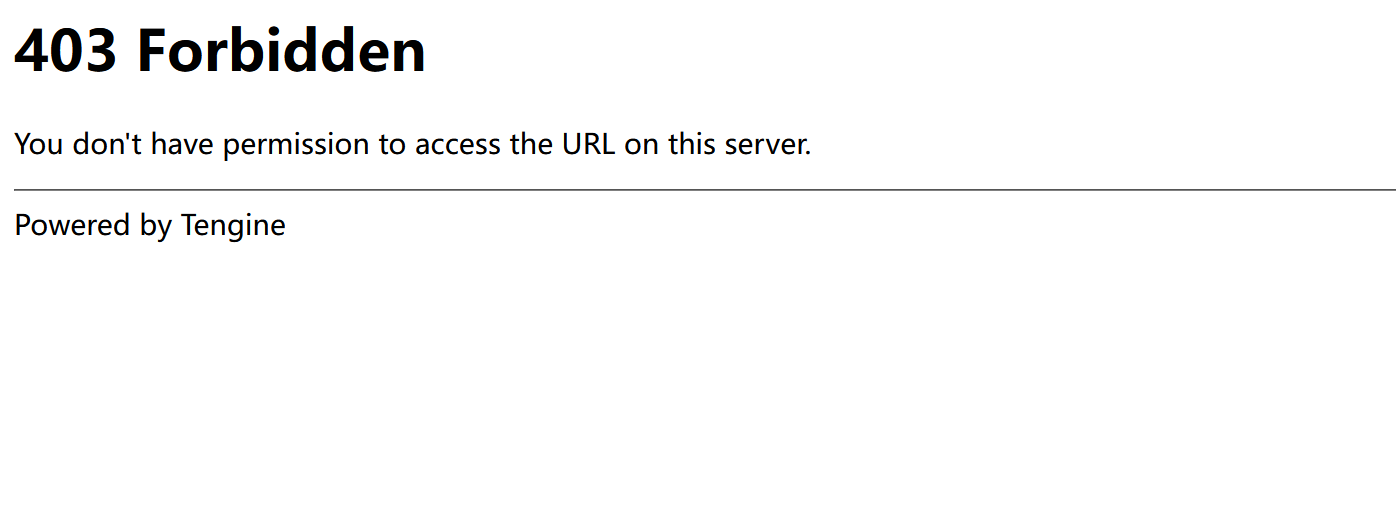
微博图床长期以来都是中国大陆访问线路质量高、图片质量高的存在。
2022年12月29日左右,微博图床图片出现了大规模403的情况。事实上,微博图床早已有防盗链手段,但极易通过html noreferer标签进行规避。
所谓防-盗链,是指通过请求Header中的Referer地址判断访问来源,仅让白名单域名访问资源的一种手段,可以降低流量成本。通常的,网站不会对noreferer防盗链开启防盗链,所以新浪和盗链用户暂且相安无事,而本次对noreferer开启防盗链,才致使出现大规模403。
很不幸,本站的图片API和部分内容都使用了微博图床,因此,一场紧急“救图”行动开始了。
临时措施
如果很不幸没有备份存在图床里的图片,我们可以选择修改referer的方式临时下载。
curl --referer可以伪装来路,从而解决403错误无法下载图片的问题,但这样未免太不方便;
Chrome浏览器安装 Header Editor ( https://chrome.google.com/webstore/detail/eningockdidmgiojffjmkdblpjocbhgh),参考下图添加修改请求头的规则,匹配规则与使用域名相符即可。
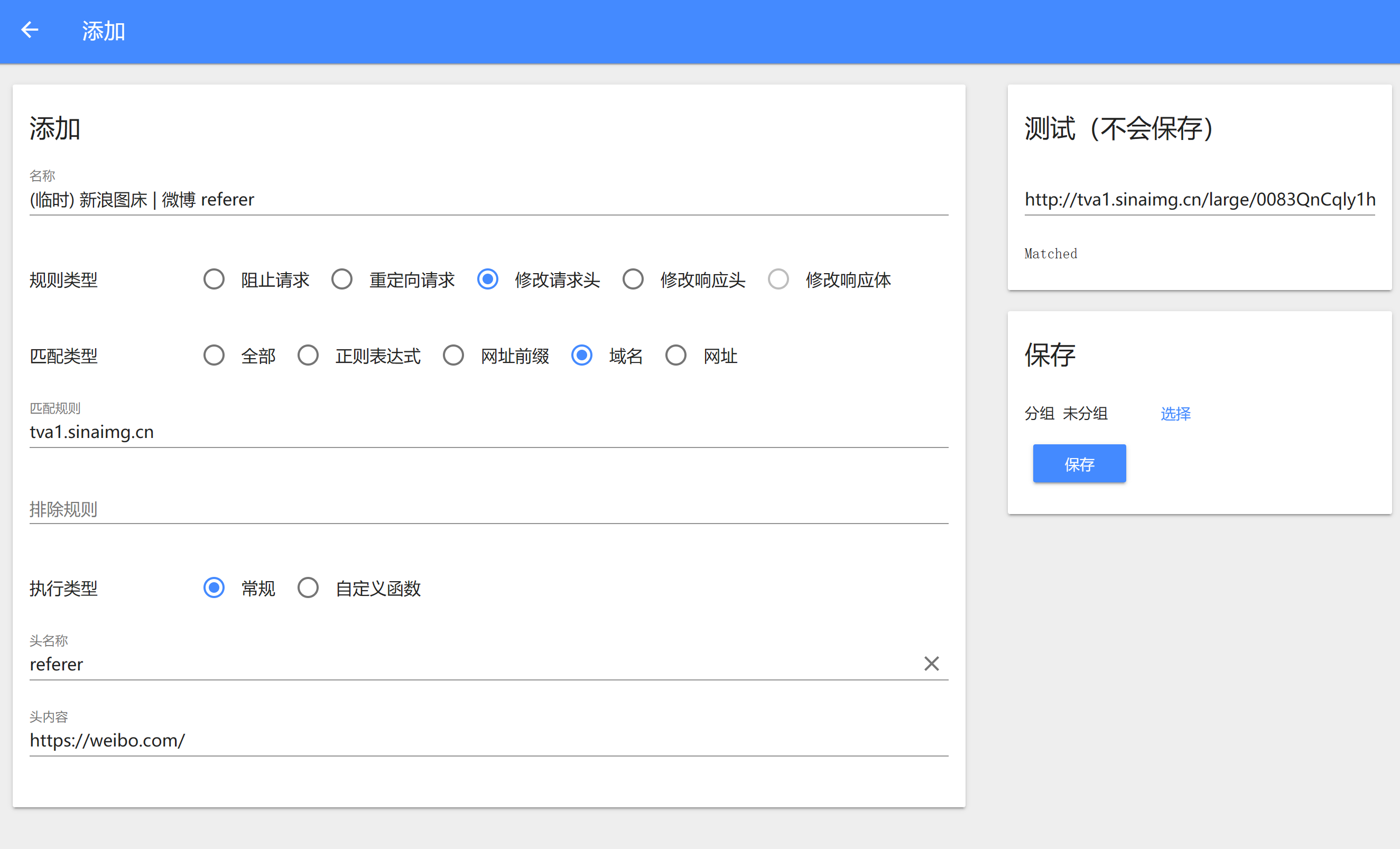
待下载图片后重新上传至其他处,替换网页上的链接即可。
掩耳盗铃
经测试,tva1.sinaimg.cn等微博图床域名已开启noreferer防盗链无疑,但tvax1.sinaimg.cn等域名似乎仍可以通过noreferer访问,如果不想将图片迁移,可以将图床域名进行替换(内容不会改变)
有二次压缩——
加前缀:https://i0.wp.com/tvax4.sinaimg.cn/large/ (第三方反向代理,风险自负)
加前缀:
https://image.baidu.com/search/down?url=http://tvax4.sinaimg.cn/large/
(百度搜索,风险自负)
个人非常不推荐这样做
如果你想稳定地提供图片,还是使用其他公共图床/对象储存吧。
一点感慨
从良心云年末促销力度明显削减,到微博图床防盗链,大家的裤腰带似乎勒得越来越紧了。
希望疫情早日过去,经济早日恢复。